Converting a PDF file to text¶
Most PDF files look like they contain well-structured text. But the reality is that a PDF file does not contain anything that resembles paragraphs, sentences or even words. When it comes to text, a PDF file is only aware of the characters and their placement.
This makes extracting meaningful pieces of text from PDF files difficult. The characters that compose a paragraph are no different from those that compose the table, the page footer or the description of a figure. Unlike other document formats, like a .txt file or a word document, the PDF format does not contain a stream of text.
A PDF document consists of a collection of objects that together describe the appearance of one or more pages, possibly accompanied by additional interactive elements and higher-level application data. A PDF file contains the objects making up a PDF document along with associated structural information, all represented as a single self-contained sequence of bytes. [1]
Layout analysis algorithm¶
PDFMiner attempts to reconstruct some of those structures by using heuristics on the positioning of characters. This works well for sentences and paragraphs because meaningful groups of nearby characters can be made.
The layout analysis consists of three different stages: it groups characters into words and lines, then it groups lines into boxes and finally it groups textboxes hierarchically. These stages are discussed in the following sections. The resulting output of the layout analysis is an ordered hierarchy of layout objects on a PDF page.
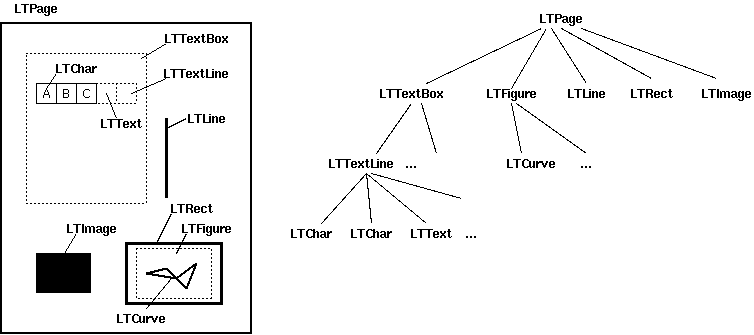
The output of the layout analysis is a hierarchy of layout objects.¶
The output of the layout analysis heavily depends on a couple of parameters. All these parameters are part of the LAParams class.
Grouping characters into words and lines¶
The first step in going from characters to text is to group characters in a meaningful way. Each character has an x-coordinate and a y-coordinate for its bottom-left corner and upper-right corner, i.e. its bounding box. Pdfminer.six uses these bounding boxes to decide which characters belong together.
Characters that are both horizontally and vertically close are grouped onto one line. How close they should be is determined by the char_margin (M in the figure) and the line_overlap (not in figure) parameter. The horizontal distance between the bounding boxes of two characters should be smaller than the char_margin and the vertical overlap between the bounding boxes should be larger than the line_overlap.
| → | ← M | |||
Q u i |
c k |
b r o w n |
||
| → | ← W | |||
The values of char_margin and line_overlap are relative to the size of the bounding boxes of the characters. The char_margin is relative to the maximum width of either one of the bounding boxes, and the line_overlap is relative to the minimum height of either one of the bounding boxes.
Spaces need to be inserted between characters because the PDF format has no notion of the space character. A space is inserted if the characters are further apart than the word_margin (W in the figure). The word_margin is relative to the maximum width or height of the new character. Having a smaller word_margin creates smaller words. Note that the word_margin should at least be smaller than the char_margin otherwise none of the characters will be separated by a space.
The result of this stage is a list of lines. Each line consists of a list of characters. These characters are either original LTChar characters that originate from the PDF file or inserted LTAnno characters that represent spaces between words or newlines at the end of each line.
Grouping lines into boxes¶
The second step is grouping lines in a meaningful way. Each line has a bounding box that is determined by the bounding boxes of the characters that it contains. Like grouping characters, pdfminer.six uses the bounding boxes to group the lines.
Lines that are both horizontally overlapping and vertically close are grouped. How vertically close the lines should be is determined by the line_margin. This margin is specified relative to the height of the bounding box. Lines are close if the gap between the tops (see L 1 in the figure) and bottoms (see L 2) in the figure) of the bounding boxes are closer together than the absolute line margin, i.e. the line_margin multiplied by the height of the bounding box.
| ↓ | |||
Q u i c k b r o w
n |
↓ | ||
| L1 | |||
f o x
|
↑ | L2 | |
| ↑ | |||
The result of this stage is a list of text boxes. Each box consists of a list of lines.
Grouping textboxes hierarchically¶
The last step is to group the text boxes in a meaningful way. This step repeatedly merges the two text boxes that are closest to each other.
The closeness of bounding boxes is computed as the area that is between the two text boxes (the blue area in the figure). In other words, it is the area of the bounding box that surrounds both lines, minus the area of the bounding boxes of the individual lines.
Q u i c k b r o w n
|
|||
j u m p s ... |
|||
Working with rotated characters¶
The algorithm described above assumes that all characters have the same orientation. However, any writing direction is possible in a PDF. To accommodate for this, pdfminer.six allows detecting vertical writing with the detect_vertical parameter. This will apply all the grouping steps as if the pdf was rotated 90 (or 270) degrees